小米AI实验室再放大招。2026年5月,下一代Kaldi团队(k2-fsa)正式开源OmniVoice——一款支持646种语言的零样本多语言语音克隆TTS系统,仅需3至10秒参考音频即可克隆任意音色,且支持跨语言合成。
极简架构打破行业惯例
OmniVoice的核心突破在于其极简的单阶段架构。传统TTS模型通常采用两阶段流水线:先将文本转为语义token,再转为声学token。而OmniVoice仅用一个双向Transformer网络,直接从文本映射到多码本声学token,省去了语义层这一中间环节。
据官方介绍,该设计带来了两项关键改进:全码本随机掩蔽策略显著提升训练效率;引入大语言模型预训练参数进行初始化,使语音合成的可懂度大幅提升,有效解决了「读不准」的问题。
性能指标全面领先
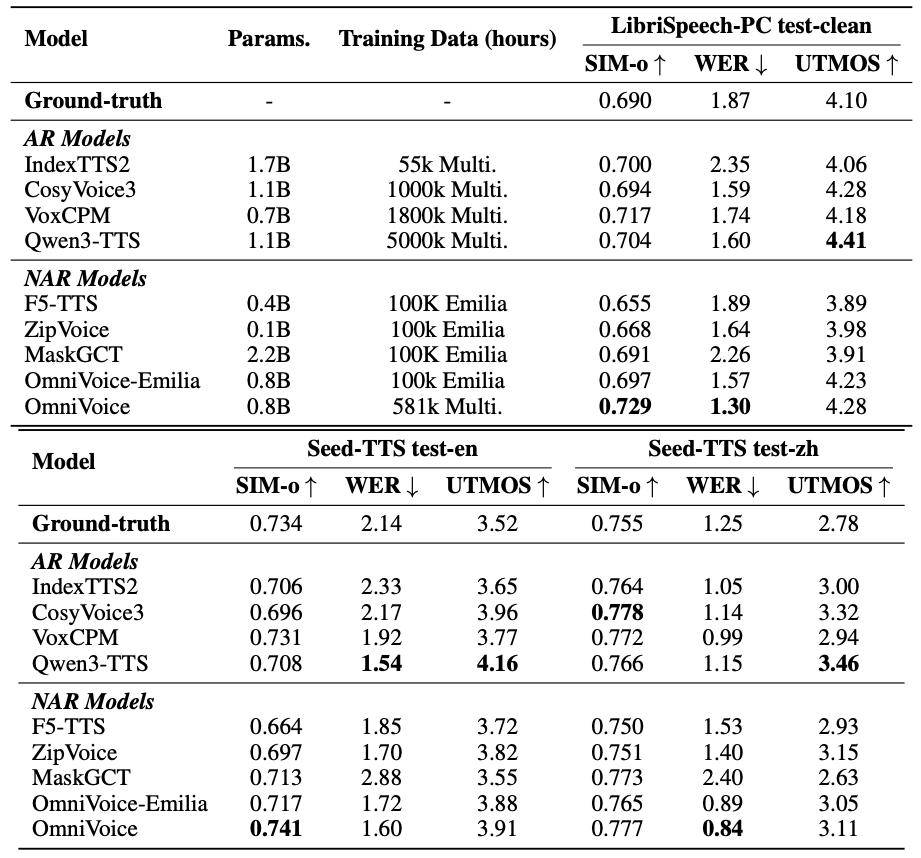
在Seed-TTS中文测试集上,OmniVoice的词错误率(WER)仅为0.84%,优于ElevenLabs v2(约2%)和阿里CosyVoice3(约1.5%)。在24种语言的盲测中,其语音相似度和可懂度均超越多款商用系统;在102种语言的测试中,可懂度逼近甚至优于真实录音。
推理效率方面,实时因子(RTF)低至0.025,合成速度比实时快40倍,生成40秒音频仅需约1秒。开发者可直接使用PyTorch推理,无需额外优化。
低资源语言的「救星」
OmniVoice使用50个开源语音数据集、共计58.1万小时数据训练而来。对于训练数据不足10小时的小语种,模型通过动态上采样技术仍能实现高质量合成,大大降低了低资源语言的语音合成门槛。
除语音克隆外,模型还支持自然语言描述定制音色(如「男,中年,极低音调」)、带噪音频自动降噪、笑声叹气等语气符号插入,以及中英文多音字和专有名词的发音纠正。
完全开源,免费商用
OmniVoice采用Apache-2.0许可证,代码和模型权重已在GitHub和Hugging Face开源。该模型参数量为0.8B,对个人和商业使用均不收费,为语音合成领域提供了首个覆盖数百语种的开源解决方案。