新加坡AI创业公司Sapient Intelligence近日开源了旗下全新层级推理模型(Hierarchical Reasoning Model, HRM)的文本版本——HRM-Text。该模型在预训练阶段展现出惊人的效率:1B参数版本仅需约46小时、约1472美元即可从零训练完成,数据用量仅为同级别常规模型的千分之一。
核心创新:双时间尺度循环架构
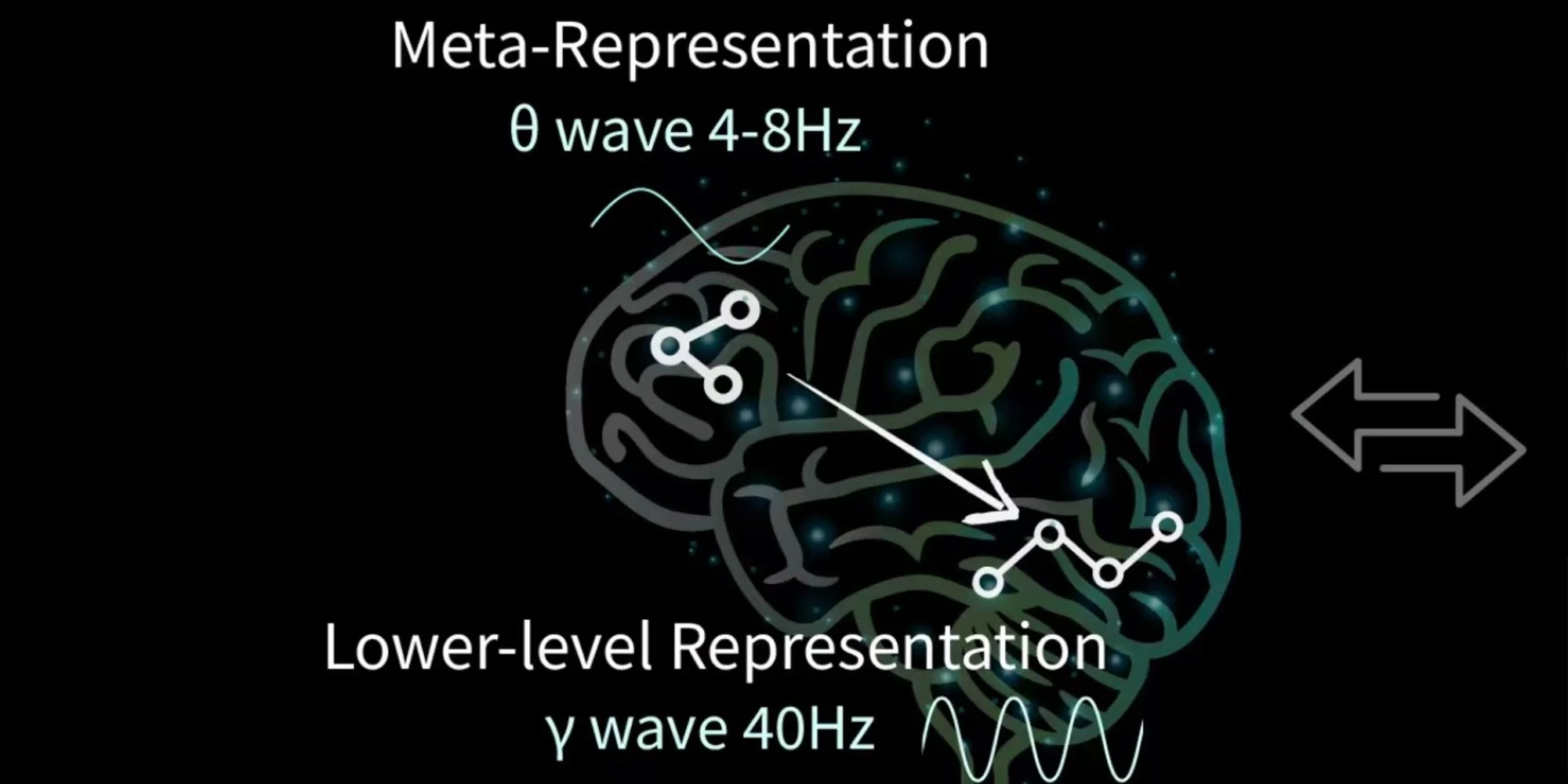
HRM-Text的设计灵感源自人脑的快慢双模式思考机制。模型内置两套Transformer模块:**高层(慢思考)**负责规划方向、理解目标,**低层(快反应)**处理细节、完成任务。这两套模块在同一批输入上交替迭代,通过状态相加交换信息。这种架构允许模型在物理参数量固定的前提下,通过增加循环次数动态拓展计算深度。
据官方介绍,该架构将基础模型预训练的算力消耗缩减了130至600倍。模型仅使用400亿(40B)个结构化Token完成预训练,远低于行业通常所需的数万亿Token规模。
训练成本对比
| 版本 | 硬件配置 | 训练时长 | 估算成本 |
|---|---|---|---|
| 1B参数 | 2台8卡H100服务器 | ~46小时 | ~1472美元 |
| 0.6B参数 | 单节点 | ~50小时 | ~800美元 |
值得注意的局限性
本次发布的仅为未对齐的纯预训练权重,模型目前只能执行前缀续写任务,无法直接作为问答助手使用。团队尚未发布RLHF对齐版本。
意义与前景
预训练门槛的断崖式下降,为许多因算力成本高昂而被搁置的模型理论提供了低成本验证的机会。Sapient Intelligence已同步开源包含数据提取、序列打包与PyTorch分布式训练在内的完整工程框架,降低了复现门槛。
该公司此前还推出了参数规模更小的27M版本HRM,在复杂推理任务中展现出与大模型竞争的潜力,引发业界关注。