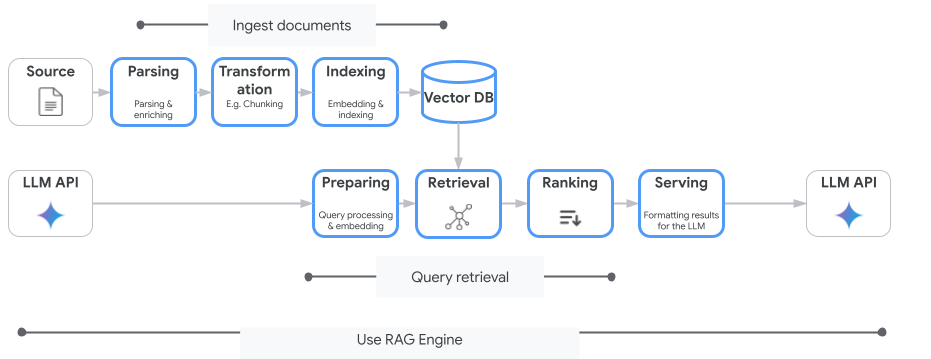
谷歌把 RAG 升级成「多智能体流水线」
谷歌研究部门与谷歌云合作推出的 Agentic RAG 架构,已在 Gemini Enterprise Agent Platform 开启公测。这套方案用一组协同工作的智能体替代了「检索一次、生成一次」的传统 Vanilla RAG 流程,把企业知识库问答从单步检索变成可反思���可补查的闭环系统。
从「检索一次」到「检索—评估—补查」
新架构的工作流围绕几个角色分工:
- Orchestrator:评估请求复杂度,决定是否需要拆解。
- Planner Agent:规划跨多个数据库的搜索路径。
- Query Rewriter:把模糊提问拆解、重构为多个精准检索词。
- Search Fanout Agent:在各数据源并发执行搜索。
最关键的升级是新增的 Sufficient Context Agent 质量控制智能体。它在生成回答前会做两件事:审查检索到的文本片段是否足够,并对照用户提问评估中间草稿的匹配度。一旦判定信息不完整,系统不会直接输出残缺或带幻觉的答案,而是指出具体的数据缺口并把反馈写回 Query Rewriter,触发定向二次检索,直到找齐所有缺失事实,再交给 Synthesis Agent 整合输出。
跨四库依然 90.1%,延迟几乎不变
在面向多源多步查询的 FramesQA 数据集上,Agentic RAG 在需要跨越 4 个不同数据库的检索场景下仍然达到 90.1% 的准确率,与单数据库检索的准确率几乎持平;双端运行的平均延迟差距控制在 3% 以内。整体相比 Vanilla RAG,事实性数据集上的准确率提升可达 34%。
对企业意味着什么
对企业用户而言,这套框架直接缓解了 RAG 落地中最头疼的两个问题:多源数据下的事实丢失与幻觉输出。借助闭环质量控制,智能体可以在不完整证据面前主动「拒答并补查」,而不是给出看起来自信但错漏的答案。同时,跨库场景下几乎不增加的延迟,也让面向客户的多源知识问答在生产环境中具备可行性。
目前该能力随 Gemini Enterprise Agent Platform 在 us-central1、us-east1、us-east4 等区域开放公测(部分区域需申请白名单),感兴趣的企业开发者可通过 Vertex AI SDK 试用。
信源: