智谱AI于4月初正式上线GLM-5V-Turbo多模态编程基座模型,并于近日补发了完整技术报告。该模型支持200K上下文窗口,可接入Claude Code、OpenClaw/AutoClaw等主流编程Agent框架,是智谱首个将视觉感知深度融入编程全流程的多模态基座模型。
架构设计三大核心
与多数将视觉作为语言模型附件的做法不同,GLM-5V-Turbo从预训练阶段就将视觉感知融入推理、规划、工具调用和执行的全流程。技术报告披露了三大关键设计:
CogViT视觉编码器:采用SigLIP2和DINOv3双教师蒸馏预训练,再用80亿中英双语图文语料做对比学习对齐,实现原生多模态理解能力。
多模态多Token预测(MMTP):用一个共享的可学习特殊token替代直接传递视觉嵌入,降低跨pipeline阶段的通信复杂度,训练更稳定。
30余项任务联合强化学习:覆盖感知、推理和Agent执行三个层级,在视频理解、3D定位、GUI Agent、多模态搜索工具调用等任务上均取得显著提升。
性能表现亮眼
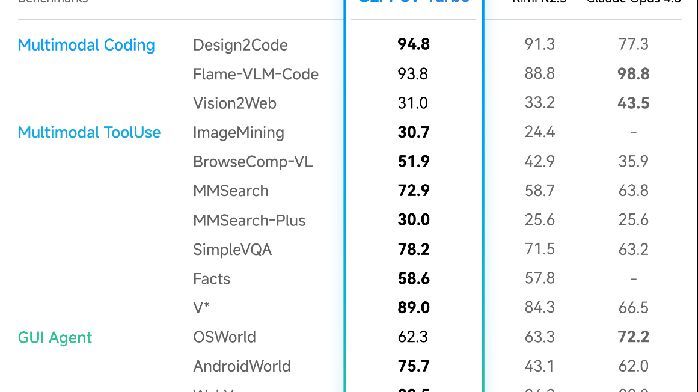
在核心基准测试中,GLM-5V-Turbo以更小参数尺寸取得领先表现:
- Design2Code 94.8:超越Claude Opus 4.6
- OSWorld 62.3、AndroidWorld 75.7:GUI操控能力领先
- MMSearch 72.9、BrowseComp-VL 51.9:多模态搜索表现优异
- MMSearch-Plus 30.0:较上一代GLM-4.6V提升近8倍
值得注意的是,纯文本编程能力在CC-Bench-V2的后端(22.8)、前端(68.4)和代码仓库探索(72.2)三项上均保持稳定,甚至反超其纯文本底座GLM-5-Turbo。
RL阶段能力提升显著
技术报告详细披露了多任务强化学习阶段的提升分布:2D图像定位+4.8%、视频理解+5.6%、3D定位+7.7%、OCR+4.2%、图表理解+7.7%、GUI Agent(OSWorld)+4.9%、多模态搜索工具调用+3.5%。团队指出,多任务RL不同于SFT常见的跨域干扰,各能力可稳定共同提升,一个领域学到的推理模式还会迁移到其他领域。
目前GLM-5V-Turbo已在Z.ai API和OpenRouter上线,完整技术报告可查阅arXiv。